
Elasticsearch
Elasticsearch란
Apache Lucene 기반의 java 오픈소스 분산 검색 엔진이다.
Elastic Search는 고성능의 실시간 검색 및 분석을 가능하게 하며, 대규모 데이터에서 정보를 빠르고 효율적으로 검색할 수 있게 설계되어있다.
ELK 스택이란?
Elastic에서 제공하는 검색 플랫폼 구조로 Elasticsearch / Logstash / Kibana 를 사용한다.
LogStash
다양한 소스(DB, csv파일)의 로그 또는 트랜잭션 데이터를 수집, 집계 파싱하는 솔루션이다.
Kibana
데이터를 시각화 및 모니터링 하는 솔루션이다.
Elastic Search의 주요 특징
Elastic Search는 대용량 데이터를 실시간으로 검색하고 분석할 수 있어, 실시간으로 인사이트를 얻어야 하는 애플리케이션에 적합하다. 그리고 데이터를 여러 노드에 분산 저장하고 처리하기 때문에 높은 가용성과 확장을 보장한다. 뿐만 아니라 데이터를 저장하고, 검색할 때 RESTful API 를 사용하여 다양한 프로그래밍 언어에 쉽게 접근하고 사용할 수 있다. 한편, JSON 형식의 문서를 저장하여 데이터 구조를 미리 정의하지 않아도 된다는 장점도 있다. Lucene 기반의 고급 텍스트 분석 기능을 제공하여, 정밀한 검색과 복잡한 Query가 가능하다.
RDBMS와 Elastic Search
이 글을 읽고 있는 독자들은 대부분 필자와 같이 관계형 DB에 익숙할 것이다. 그러므로 Elastic Search에서는 관계형 DB에서 사용하는 개념과 비슷한 개념들을 아래와 같이 대응 시켜 이해해보자.
| 개념 | RDBMS | Elasticsearch |
|---|---|---|
| 데이터베이스 | Database | Index |
| 테이블 | Table | Type |
| 행 | Row | Document |
| 열 | Column | Field |
| 인덱스 | Index | Analyze |
| 기본키 | Primary key | _id |
| 스키마 | Schema | Mapping |
| 관계 | Relational | Parent/Child |
| 쿼리 | SQL | Query DSL |
Elastic Search 아키텍쳐 및 용어
Elastic Search에서 사용하는 대부분의 개념은 RDBMS에 존재하는 개념들이다. 먼저 아키텍처를 살펴보자.
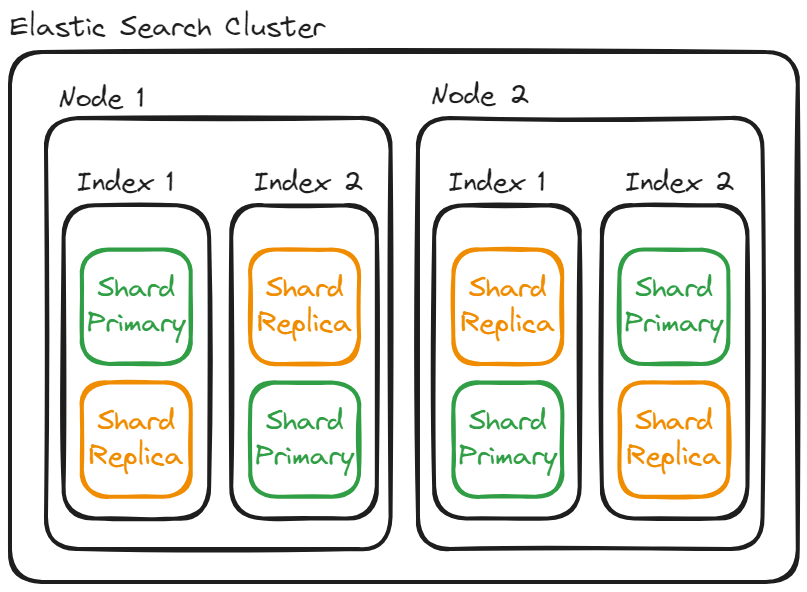
Cluster
Cluster란 Elastic Search에서 가장 큰 시스템 단위를 의미하며, 최소 하나 이상의 노드로 이루어진 노드들의 집합이다. Cluster간 데이터 접근 및 교환을 할 수 없는 독립적인 구조를 이루고 있으며, 상황에 따라 여러대의 서버가 하나의 클러스터를 구성할 수도 있고, 한 서버에 여러 개의 클러스터로 이루어 질 수도 있다.
Node
| Node Name | 역할 |
|---|---|
| Master-eligible | 인덱스 생성 및 삭제, Cluster 노드들의 추적 및 관리, 데이터 입력시 할당할 샤드 배정 |
| Data | CRUD와 관련된 Node, 자원소모가 많아 모니터링 필요 |
| Ingest | 데이터 변환, 사전처리 파이프라인 실행 |
| Coordination only | 로드밸런서 역할 수행 |
Elastic Search를 구성하는 하나의 단위 프로세스를 의미한다. 역할에 따라 Master-eligible, Data, Ingest, Tribe 노드로 구분된다. 먼저 Master eligible node는 클러스터를 제어하는 마스터로 선택 될 수 있는 노드이다. Master node는 index를 생성, 삭제하고 다른 node를 추적, 관리 하며 데이터 입력 시 어느 shard에 할당할지를 정한다. Ingest node 사전 처리 파이프라인을 실행한다. Coordination only node는 data node와 master-eligible node 의 일을 대신하여 로드밸런서와 비슷한 역할을 하기때문에 대규모 클러스터에서 큰 이점이 있다.
Index / Shard / Replica
Index는 RDBMS에서 database와 같은 개념이다. Shard와 Replica도 새로운 개념이 아닌 분산 데이터베이스 시스템에 존재하는 개념이다.
Sharding은 데이터를 분산해서 저장하는 방법을 의미한다. Elastic Search에서는 index를 여러개의 Shard로 스케일 아웃한다.
Replica는 또 다른 형태의 Shard로 노트를 손실했을 경우 데이터의 신뢰성을 보장하기위한 복사본이다. 그래서 다른 Replica는 서로 다른 노드에 존재하는 것이 좋다.
댓글남기기